
At Profound, our LLM Perception system ingests tens of billions of events daily, tracking how brands appear across AI platforms like ChatGPT and Google Gemini. That's how we see what's happening. But seeing isn't enough.
The question that drove us to build Cortex: how do you turn that visibility data into intelligent features without writing custom code for every new capability?
What is Cortex
Cortex is a high-performance agent runtime we built from scratch. It sits within Magi, our internal system for everything that uses generative AI, and executes complex, multi-step operations as directed graphs. When a feature needs to query our data, call an LLM for analysis, transform the results, and push insights downstream, Cortex figures out what can run in parallel, manages dependencies between steps, and streams results back in real time.
If LLM Perception is how we sense the AI landscape, Cortex is how we reason about it.
Why performance matters
Our agent builder is Turing-complete. Any problem we can describe, we can solve by composing agents. Need to analyze sentiment patterns in competitor mentions? Build an agent. Need to generate recommendations based on visibility trends? Build an agent. Need to alert when a brand's presence shifts? Build an agent.
This abstraction is what lets us ship AI features fast. Instead of writing custom code for each capability, we compose reusable building blocks. The agent builder becomes a universal tool maker.
Now consider what's happening with large language models. They're calling more tools, more often. What started as occasional function calls has evolved into systems that chain dozens of tool invocations to complete complex tasks. Each tool call can become an agent. Each agent hits Cortex.
Today, our agents power features that humans interact with. But we're building for a different future, one where autonomous AI systems are the primary consumers. When an AI system needs competitive intelligence about a brand's visibility, it won't wait for a dashboard. It will call our tools directly, potentially thousands of times per minute, composing and recomposing agents to answer questions we haven't anticipated.
In that world, Cortex isn't just infrastructure. It's the foundation that makes autonomy possible. The difference between a 50ms agent execution and a 500ms one isn't just latency. It's whether AI can reason at the speed it needs to.
We built Cortex to be fast not because we needed it today, but because we can see where this is going. The usage curve for tool-calling will be exponential once AI operates autonomously. We'd rather have headroom than bottlenecks.
Why we built our own
We tried the alternatives first.
Existing orchestration systems are excellent, but they were designed for different problems. We needed real-time streaming, complex graph execution, tight integration with LLM providers, and the ability to scale horizontally without costs growing faster than usage.
We also needed to understand every line of code that powers our AI features. When enterprise clients depend on your platform, black boxes aren't acceptable.
The architecture
Cortex separates the API layer from the execution layer, connected by a high-performance messaging backbone.
The API layer is a thin, fast gateway. It handles authentication, request validation, and client communication. When something triggers an agent, the API validates the request, persists the necessary state, and hands off immediately. It doesn't execute agents itself.
The execution layer is where the real work happens. Agent jobs flow through a distributed queue, picked up by Achiral workers that handle node-by-node execution. This separation means the API stays responsive regardless of how heavy the agents become. A complex agent with dozens of LLM calls doesn't block new requests or slow down streaming updates.
Between them, a messaging layer handles job distribution and event streaming. When an agent executes, events flow back in real time. Node started, node completed, output produced. The API streams these to clients without polling.
This gives us independent scaling. API instances scale with request volume. Achiral scales with execution load. Neither bottlenecks the other.
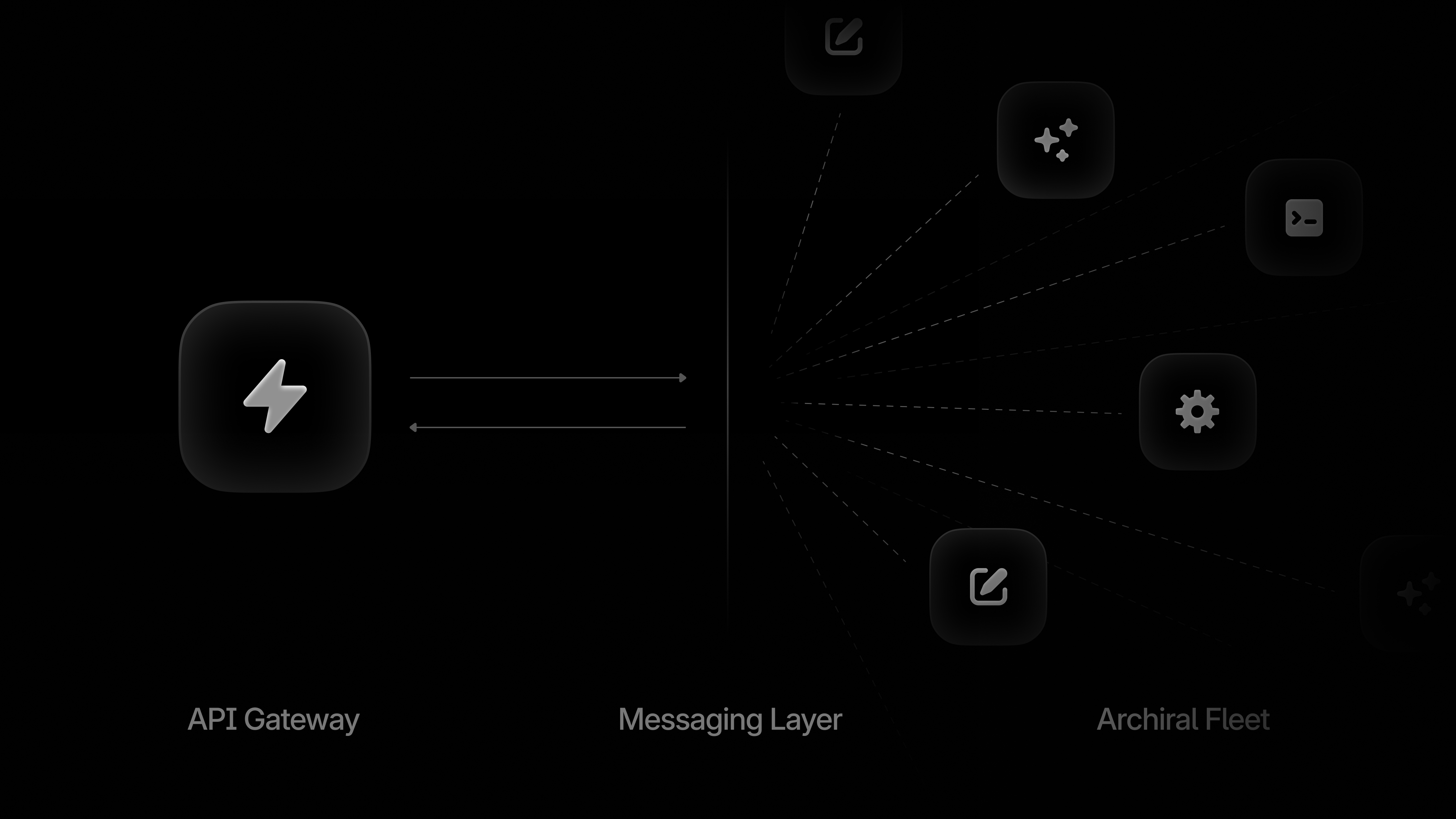
Achiral: the worker fleet
Our distributed Magi Achiral workers are stateless and interchangeable. They pull jobs from shared queues and execute them. No worker is special. No worker holds unique state. Spin up ten or a hundred, and they compete fairly for work without coordination overhead.
Scaling becomes trivial. During spikes, we go from a handful of workers to dozens in seconds. Failure becomes cheap. If a worker crashes mid-execution, another picks up the work. No state is lost because no state was held.
This architecture was designed with autonomous AI in mind. When tool calls spike unpredictably, the system scales without human intervention. It breathes with the load.
Real-time visibility
Clients shouldn't wait for a complex agent to complete before seeing results. They should watch it unfold.
Cortex streams execution updates to the browser in real time. As each node completes, the event flows immediately to the client. The UI updates live, showing progress through the agent graph.
When an agent involves dozens of steps across data queries and LLM calls, watching execution node-by-node transforms how quickly teams identify issues. If a browser loses its connection mid-execution, it reconnects and replays missed events. Clients never lose visibility, even through network interruptions.
What's next
We recently released Agents to all our enterprise clients. The foundation is in place, and we're already working on what comes next.
Sandboxed execution environments. We believe future agents should be empowered to do what humans can do on computers: browse the web, interact with applications, manipulate files, run code. To make that possible safely, we're building a sandbox runtime from scratch. Each agent gets an isolated environment where it can operate with full capability but zero risk to production systems. This is the infrastructure that turns agents from predefined sequences into truly autonomous problem-solvers.
Multi-agent orchestration. This is where we're headed. Cortex is designed to handle the load of autonomous, containerized agents calling tools. The next step is Magi orchestrating multiple agents working together, coordinating specialized AI systems that collaborate on complex analytical tasks.
We're not building for today's workloads alone. We're building for a future where AI agents are the primary consumers of analytical tools, where agents compose dynamically, where the intelligence layer needs to keep pace with machine-speed reasoning.
Cortex is the foundation. We're just getting started.
Interested in working at Profound? Take a look at our careers page.