Context
When ChatGPT answers a question, it sometimes reaches out to the web, citing sources the way a researcher would. For publishers, brands, and marketers, this creates a new battleground: who gets cited, and why?
We analyzed approximately 700,000+ conversations from U.S.-based, English-language users on ChatGPT.com (October–December 2025) to understand how ChatGPT sources the web. The findings reveal a new attention economy where the rules of answer engine optimization are being rewritten and the winners aren't always who you'd expect.
The Bottom Line
Three insights matter most:
- Turn 1 is everything. Users' opening questions trigger web searches; follow-ups rarely do. Turn 1 is 2.5× more likely to trigger citations than turn 10, and nearly 4× more likely than turn 20. If you want to be cited, you need to win the "first question" the query that kicks off a research journey, not the clarifying follow-up
- Wikipedia is the default knowledge layer (~1 in 6 cited conversations). Don’t try to beat it but be the next source after it, answering what it can’t. So do Wikipedia hygiene (keep key pages accurate + well-sourced, don’t try to fill every gap) and focus on showing up in the right domain cluster, citations tend to come in packs, so aim to consistently co-appear alongside the trusted domains already adjacent to your topic (e.g., regulators, top journals, major institutions), not just your own site.
- Sources travel in packs. ChatGPT doesn't pick one winner. It cites competitors side by side. It is important to know your citation neighbors.
Search Happens Early, Then Drops Off
About 18% of ChatGPT conversations trigger at least one web search. That rate held steady across all three months we studied. But when those searches happen tells the real story.
Why the decay? We hypothesize that opening questions often require factual grounding → "what is X?", "how does Y work?", breaking news. Follow-up turns tend to be clarifications, deeper dives, or creative tasks that don't need fresh web data.
What this means: The first question in a conversation is prime real estate. Optimize for the queries that start research journeys, not the ones that continue them.
When ChatGPT Searches, It Doesn't Settle for One Source
Among conversations that include citations:
- ~6 unique citations per conversation (trending upward from October to December)
- ~4 unique citations per turn on average when a turn includes any citations
- 66% of cited turns have 1–4 unique sources
The model triangulates. When it searches, it pulls from multiple sources rather than relying on a single authority. The rising citations-per-conversation trend may reflect more complex queries over time, or improvements in the model's sourcing behavior.
What this means: Getting cited once doesn't guarantee prominence. You're competing for share of voice within a set of sources, not for sole ownership of an answer.
The Citation Economy: Wide but Unequal
No single source dominates. But the distribution is highly unequal. A small number of domains capture disproportionate share while hundreds of thousands split the rest.
Interpretation: The citation economy is a "wide but shallow" market. No single source absolutely dominates but the distribution is highly unequal (high Gini). Everyone has a chance; few win big.
Finding Who Wins: The Top Sources
Wikipedia appears in nearly 1 in 6 conversations with citations. It's the de facto knowledge layer, the place ChatGPT goes first for baseline facts.
What this means: Authority comes in different flavors. Wikipedia wins on breadth and neutrality. Reddit wins on authenticity and specificity.
Co-citation Clusters: How Sources Travel Together
Sources cluster by domain expertise. We analyze conversations with at least one citation to understand which sources appear together (co-cited).
These are the pairs of domains most often cited together in each vertical.
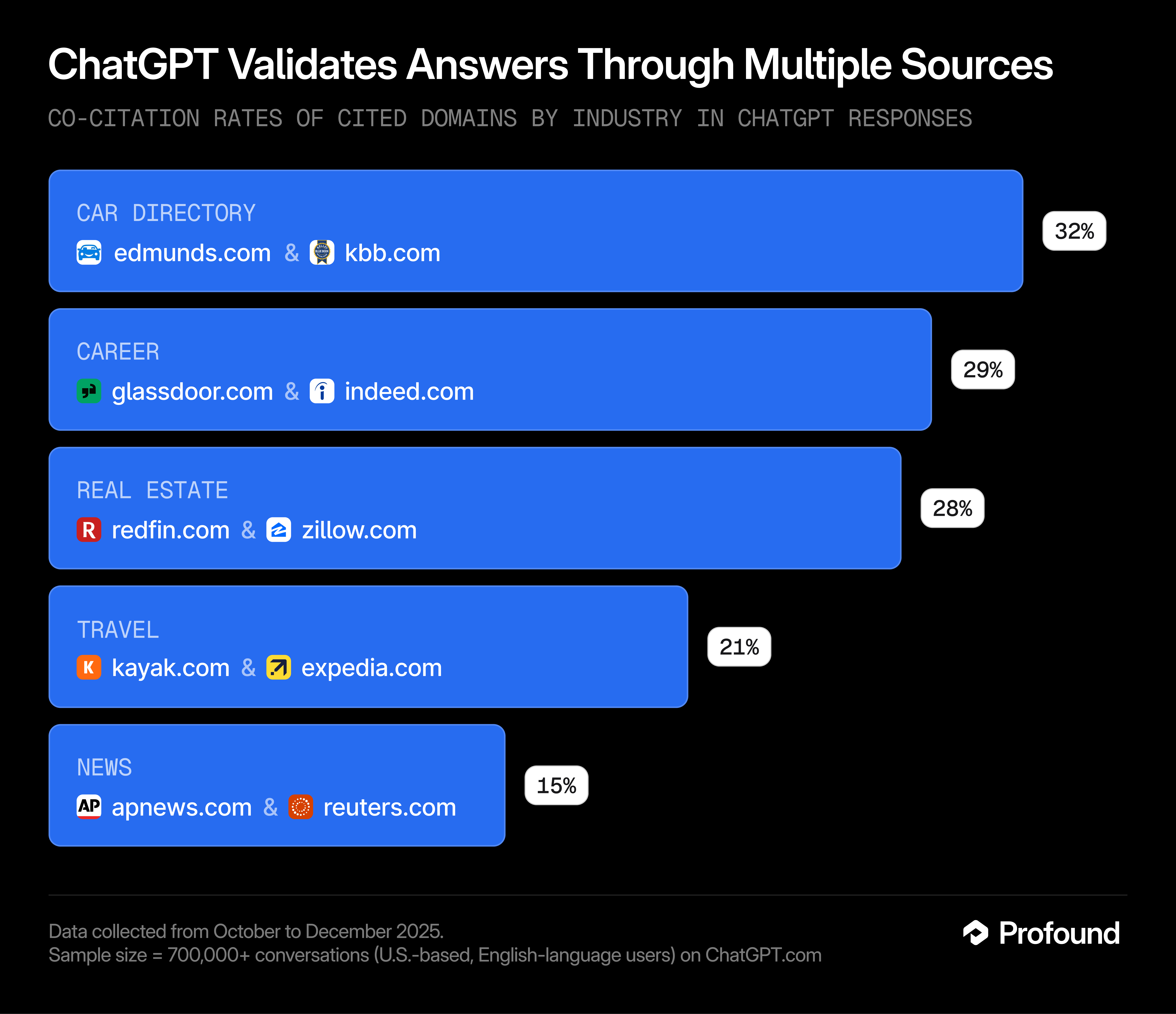
Other top pairs: NerdWallet + The Points Guy (14%) in personal finance, The Verge + TechRadar (10%) in tech news, and MDPI + NIH (7%) in health
Co-citation rate: Of all conversations that cited either source, what percentage cited both?
What this means: Know your citation neighbors. If you're a career site, you're being compared to Glassdoor and Indeed in the same conversation. If you're a travel brand, you're likely appearing alongside Kayak and Expedia. Your content strategy should account for what your competitors are saying, because ChatGPT is reading both.
What This Means for Your AEO Strategy
Win the first question. The queries that start research journeys are where citations concentrate. "What is," "how to," "best way to." Build content for the question someone asks before they know exactly what they want.
Be the source after Wikipedia. You won't out-Wikipedia Wikipedia. Be the next step: deeper analysis, current data, expert opinion it can't provide.
Own your cluster. If you're a B2B software company, the question isn't how to beat Wikipedia. It's how to become the source that appears alongside the analysts and review sites your buyers already trust.
Methodology Notes
- Scope: U.S.-based, English-language users on ChatGPT.com, October–December 2025
- Sample: ~730,000 conversations containing at least one web citation
- Note: Wikipedia and Reddit were excluded from co-citation pair analysis due to their outsized presence across all clusters/industries
- Cluster labels (e.g., "Car Directory," "Travel") are descriptive names we applied based on domain function, not from an external taxonomy.
Ready to see how our AI visibility tool works for your agency? Get a demo of Profound's Agency Enterprise plan or get started with our Agency Growth plan instantly.