
When a user types a question into an AI engine, the engine doesn't always search for exactly what was typed. It fans out: sometimes expanding a single prompt into a dozen distinct queries, sometimes departing completely from the original intent. We tracked 10,000 prompts across three major AI engines over 14 days. Here’s what we found:
- ChatGPT acts as a researcher. It casts a wide net of unique queries that are semantically similar to the user prompt but lexically different, translating natural language into fact-retrieval strings.
- Perplexity is the closest to classic search. It generates fanout queries per prompt at nearly 1:1 and stays closest to the original user prompt across wording, structure, and task framing.
- Copilot is a compressor. It rewrites prompts into a small set of shorter, search-engine-native strings — similar edit depth to ChatGPT, but producing far fewer unique queries.
This means that “AI visibility” can’t be a one-size-fits-all strategy. The retrieval mechanics across engines define the playing field.
The difference isn't how many queries fan out, it's whether they repeat
All three engines fire a similar number of fanout queries per execution: about 1.4 to 2 searches per prompt run. That's not where the gap is.
The gap is in what happens on the next run: 91% of ChatGPT's queries are unique. The engine almost never fires the same search string twice for the same prompt. Perplexity's uniqueness rate is just 14%: for the typical prompt, it issues the same one or two queries on every daily run. Copilot sits at 47%.
What this means: A single check on Perplexity gives a reasonably stable read on how your brand is being retrieved. ChatGPT generates different query variations each time, meaning any one check only captures one of many possible retrieval paths. Monitoring needs to be ongoing on ChatGPT in a way it doesn't on Perplexity or Copilot.
How engines alter intent and question type
Every engine converts prompts into direct information lookups
Regardless of what a user originally asked — advice, a recommendation, a summary, a comparison — fanout queries across all three engines skew toward simple, direct fact-retrieval. A prompt asking "what's the best way to build a social media strategy for a new brand?" is likely to generate fanouts searching for specific tactical facts, not strategic frameworks.
Perplexity most consistently maintains original intent. Product and shopping queries stayed on-topic 74% of the time; food and recipe queries 71%. Copilot was the most likely to reframe niche requests as generic information searches (43% consistency for specific lifestyle queries).
What this means: Content that answers specific, concrete questions outperforms content organized around broad themes on every engine. The retrieval layer is looking for facts, not overviews.
Perplexity and Copilot strip the question; ChatGPT keeps it
On Perplexity and Copilot, user questions get converted into bare keyword phrases, the classic search box format. A "how" prompt routes to keyword form 93% of the time on Copilot and 78% of the time on Perplexity. A user asking "how do I choose a mattress for back pain?" is likely triggering a search for "best mattress back pain". The conversational framing disappears entirely.
ChatGPT is different. It preserves question structure far more often. A "how" prompt stays question-form 31% of the time, a "why" prompt 40%. The engine is treating the fanout like an internal research brief, not a search box input. Optimizing for how a person naturally phrases a question carries more signal here than on the other two engines.
"Best" queries are the most stable surface across all three engines
A prompt framed as "best [product/service]" stays in that form 65% of the time on Perplexity, 52% on Copilot, and 39% on ChatGPT. "Which" and "where" queries are the least stable, collapsing to keyword form at high rates on all three.
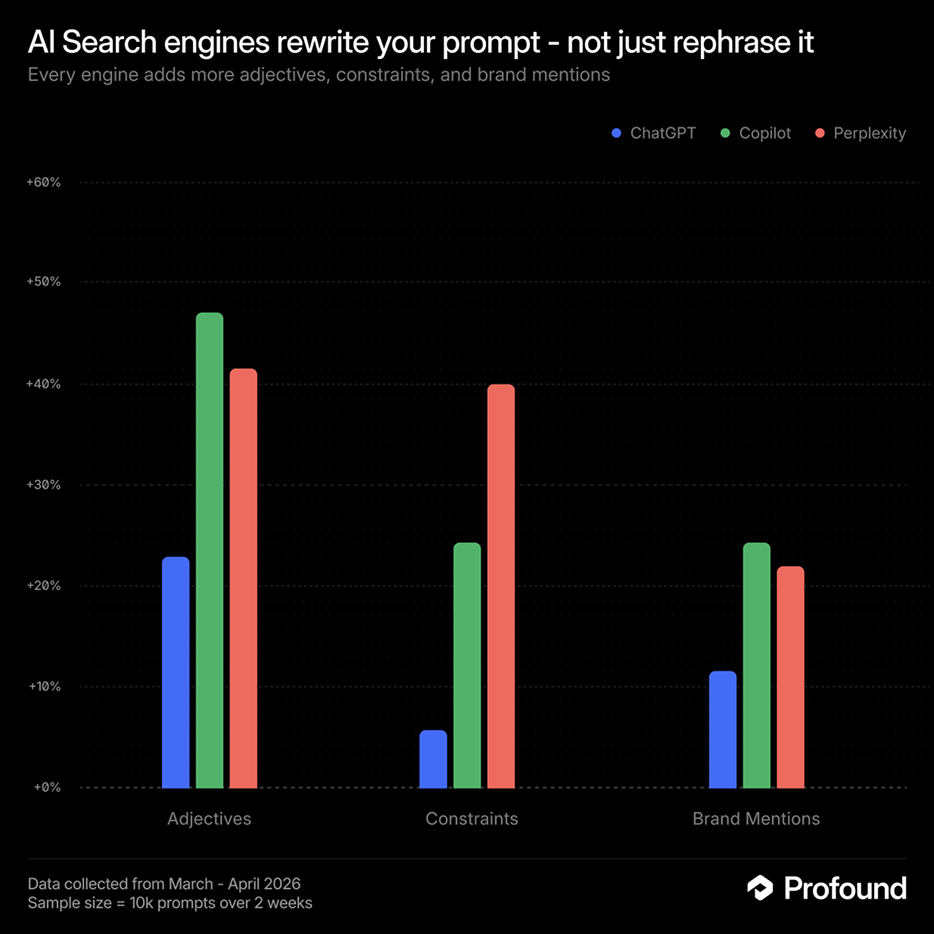
What survives the rewrite: brands, adjectives, constraints, and location
Across ChatGPT, Perplexity, and Copilot, the fanout layer preserves the broad shape of a user's prompt but strips much of the nuance, with each engine doing so in different ways and at different rates.
How different are the actual queries?
We measured word-level overlap between every prompt and every fanout query it generated. The results are the clearest expression of the researcher/classic search/compressor distinction.
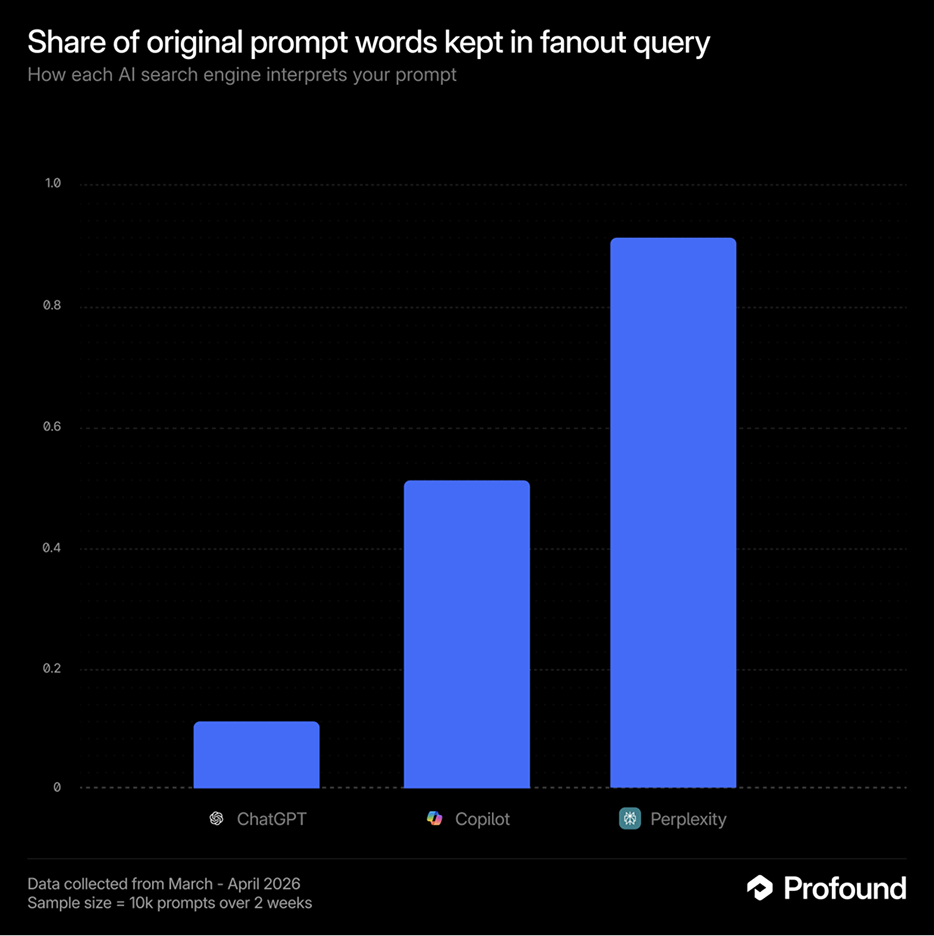
Perplexity: 88% word overlap. Its internal search queries stay very close to the prompt. In most cases, the fanout looks like a lightly cleaned-up version of what the user typed. The engine behaves like a literal retriever, which means traditional keyword coverage remains a strong proxy for what Perplexity is likely to search.
Copilot: 50% word overlap. About half the original words survive. The core meaning usually remains intact, but the phrasing gets compressed. Qualifiers are stripped, wording is standardized, and the prompt is reshaped into something closer to a conventional search query. It preserves the ask, but in a narrower, cleaner form.
ChatGPT: 13% word overlap. This is a different behavior entirely. In the typical prompt, the most divergent fanout query shares barely one word in eight with the original. ChatGPT is not just rewording the prompt. It is generating new retrieval paths that pursue the same goal through different vocabulary, adjacent concepts, and alternate framings. A prompt about “eco-friendly protein powder for endurance athletes” can fan out into internal search queries about plant-based supplements, sports nutrition research, or ingredient-level performance topics that share little surface language with the original phrasing.
That makes ChatGPT much harder to understand through keyword matching alone. The visible prompt and the actual internal search queries can be very different things. In practice, the retrieval layer may be operating on terms that never appeared in the user’s original wording at all.
What this means for your brand
The way users phrase a prompt is not the way AI engines search for answers. By the time a query reaches the retrieval layer, it has been rewritten, compressed, or expanded, and each engine does it differently. That gap has direct implications for how brands show up.
Perplexity and Copilot reward keyword-dense, search-optimized content. Both collapse prompts into keyword-style queries. Content structured around category names, product attributes, and clear feature labels is more likely to survive the rewrite.
ChatGPT requires a broader content footprint. It preserves more natural-language framing and generates less repeatable query variations, so keyword matching alone won't reliably capture visibility. Brands need content that can be retrieved across a wider range of phrasings — not just the ones users type but the ones the model invents.
"Best [category]" is worth owning. Across all three engines, "best" prompts are among the least likely to be reformatted, making them one of the most durable entry points in AI search.
Location signals carry through. Geographic qualifiers are the most consistently preserved element across engines. For brands with local relevance, clear location signals are one of the most reliable ways to stay visible through the rewrite.
Constraints and comparisons are fragile. Price points, filters, and multi-brand competitive sets are frequently dropped or reinterpreted. Visibility strategies need to account for the simplified version of the prompt, not just the original.
Methodology
We tracked a random sample of 10,000 prompts over a 14-day window (late March – mid April 2026), running each prompt against ChatGPT, Perplexity, and Copilot. Not all prompts were run on all engines every day. For each run, we captured the full set of search queries the engine sent to its underlying retrieval layer.
- Intent classification, question-type classification, and brand tagging were performed using GPT-5-nano.
- Structural features (adjective count, brand count, numerical constraints, location presence) were extracted programmatically from the raw prompt text.
- Query similarity was measured between each original prompt and each fanout query using multiple methods, including semantic similarity and word-level overlap. We report the typical worst-case divergence per prompt (i.e. the most different query generated in a given run, across all prompts).
- Query uniqueness was computed as unique query strings divided by total query executions, capturing how often the engine repeats itself independent of run frequency.
Results were stable across the 14-day window. Day-of-week variation was small relative to cross-engine differences.
Getting started
If you want to understand what AI engines are actually searching for when users mention your brand, Profound tracks your visibility across ChatGPT, Perplexity, and other AI platforms in real time — talk to our team to see how.