Technical answer engine optimization (AEO) has an evidence problem. For every tactic with real data behind it, five more are being sold on confidence alone: spin up markdown mirrors of your site, stuff llms.txt with marketing copy, add one magic schema type, and watch the citations roll in. Teams under pressure to show progress on AI visibility are being duped into buying checklists nobody has tested.
The confusion is legitimate. Every LLM provider runs its own set of bots, each with its own purpose and behavior, and all of them change fast enough that anyone claiming to have the exact, complete list of what you must do to be perfectly crawlable by AI is ahead of the evidence. Nobody has that list. It doesn't exist yet, and given how quickly the platforms ship, it may never hold still long enough to write down.
But “we can't know everything” is a long way from “we know nothing.” Most of what influences AI crawlability is technical SEO, which you already know how to do. The rest comes down to testing tactics one at a time and measuring whether they changed anything.
What technical AEO is (and what it isn't)
Technical AEO optimizes for one thing: enabling AI crawlers and agents to find and understand the right pages on your site. Every tactic either serves that goal, or it doesn't matter. That test alone disqualifies a surprising share of the advice in circulation.
The overlap with technical SEO is heavy but not complete. Canonical links and noindex tags are load-bearing in traditional SEO and do nothing for AEO; an LLM fetching your page to answer a live question doesn't deduplicate an index or honor your canonicalization preferences. Copy your SEO checklist wholesale, and you'll waste effort in one direction while missing AEO-specific work in the other.
The bot ecosystem is also messier than search ever was. OpenAI alone runs separate crawlers for model training, search indexing, and real-time retrieval, each behaving differently. Anthropic, Perplexity, Google, and the rest add their own bots with their own quirks, and the behaviors shift from month to month. This is why the "complete AI crawlability checklist" genre should make you suspicious. The nuances are too many, and the ground is moving too fast for one to exist.
The defensible posture has three parts. Get the fundamentals right, because they're well-evidenced and mostly cheap. Baseline your crawlability, so you know what bots are doing on your site today. Treat everything else as a hypothesis to test against that baseline.
Measure crawlability before you optimize anything
Optimizing before you've baselined is guessing. Before changing a single template, you want answers to four questions:
- Which AI crawlers visit your site
- Which pages they read
- How often they come back
- Where their requests fail
Your web analytics can't answer any of them. AI crawlers don't execute JavaScript, so client-side tools like GA4 never see them; the only place this data exists is at the server or CDN layer. That means raw server logs, the bot views inside CDN dashboards from Cloudflare, Akamai, or Fastly, or a purpose-built tool.
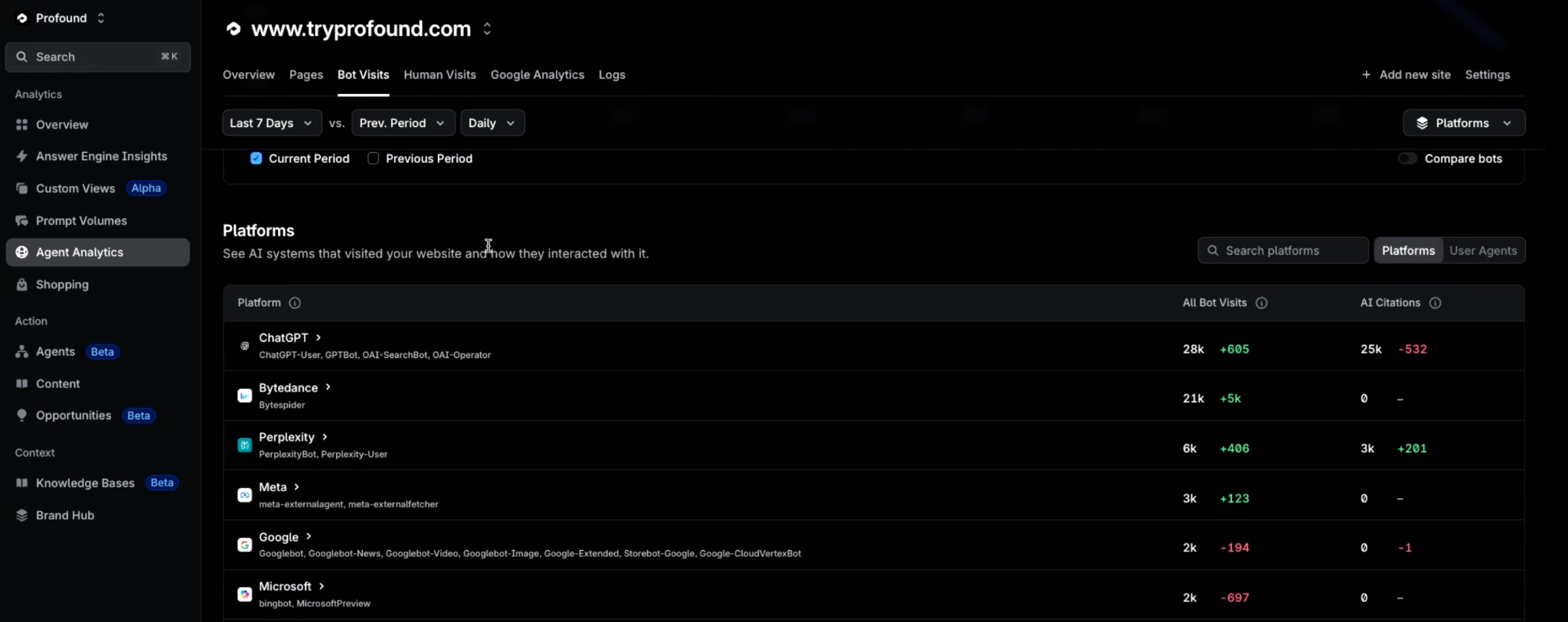
One domain, one week: six AI platforms running more than a dozen distinct crawlers, each with its own job. Profound's Agent Analytics breaks bot traffic down by platform and individual user agent.
Profound's Agent Analytics reads that layer directly, integrating with the CDN or server to classify AI traffic by platform, user agent, and intent without log-wrangling on your side. It also verifies bots before counting them, which matters more than it sounds: a meaningful share of traffic claiming to be GPTBot is spoofed, and a baseline built on unverified user-agent strings is, in effect, noise.
Whatever the source, the baseline should capture:
- Bot visits broken down by platform and purpose. A retrieval or assistant bot reading a page means that content is in active consideration for AI answers; a training bot visit is a different signal with different implications, and an indexing bot is building the library both draw from.
- Pages accessed versus pages you want accessed. If bots are crawling your blog archive and skipping your product pages, that gap is your priority list.
- Non-200 responses served to bots: redirect chains, 404s, timeouts. Every one is a failed retrieval.
- Crawl frequency over time, so you can spot changes when you make them happen, and when the platforms do.
This baseline pulls double duty. It tells you which fixes will have the greatest impact and serves as the control group against which all subsequent tests are judged.
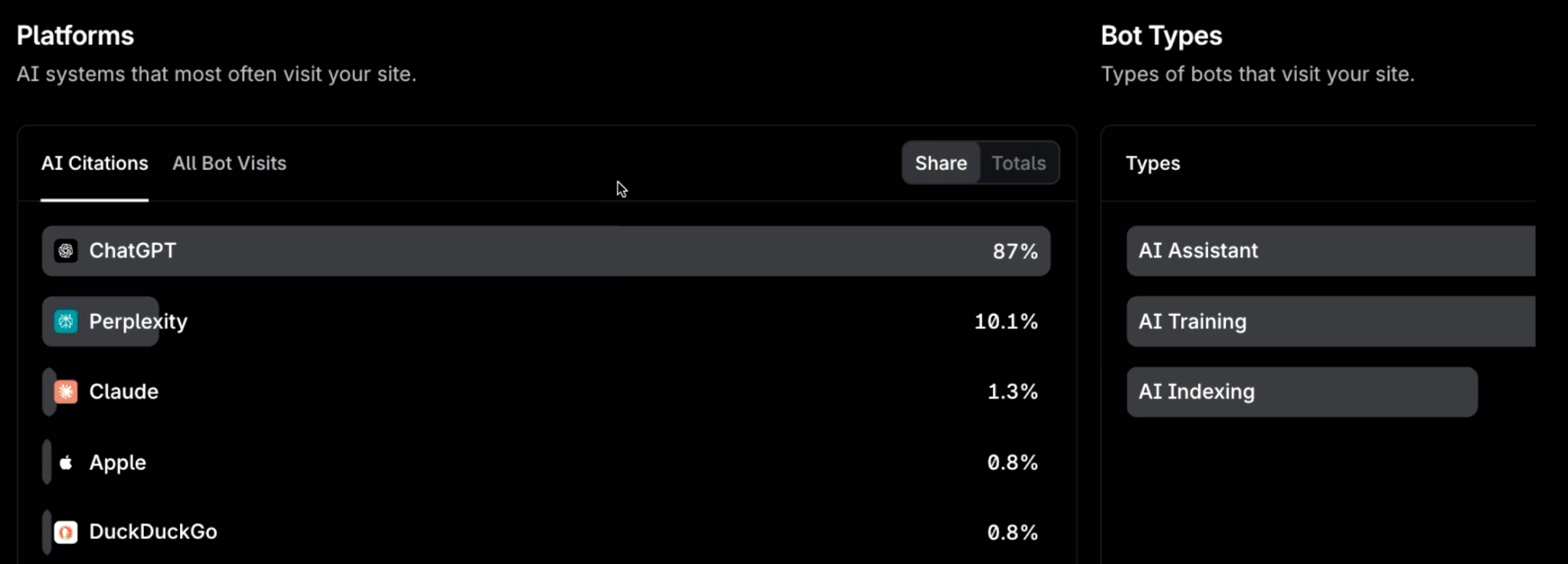
Platform share alongside bot type tells you not just who's crawling, but why: assistant, training, and indexing visits each mean something different for your strategy.
The fundamentals: Where technical SEO carries over
The boring answer is the true one—good technical SEO gets you most of the way to AI crawlability. What changes between the disciplines is emphasis, not the work itself.
There are five areas that deserve particular attention.
Robots.txt and bot access
The most basic requirement for AEO is that AI crawlers and agents can reach your domain at all. Unless you have a deliberate reason to block specific LLMs or sections of your site, we recommend a standard permissive robots.txt file.
If your company blocked GPTBot and its peers in 2023, when that was a defensible legal or brand call, the block may still be live and long forgotten. Checking what you block, deliberately or by accident, takes ten minutes and removes the one absolute barrier to AI visibility.
Profound's crawlability diagnostics flag robots.txt blocks at the page level, as well as CDN rules that quietly reject non-browser user agents.
Internal linking and crawl depth
A solid internal link structure is how AI bots reach your key pages efficiently. Content buried more than two or three clicks deep hurts discoverability, and your most important product and information pages should sit shallower still. Pointing plenty of internal links to priority pages helps both traditional SEO and AEO.
The AEO-specific twist is tolerance. Bots fetching pages in real time operate under latency constraints, and they may be less forgiving of redirect chains and other non-200 responses than Googlebot has trained you to expect. Audit your internal link profile for chains and broken paths more often than your SEO calendar alone would call for.
Page speed, TTFB, and server-side rendering
A retrieval bot fetching your page is in the middle of answering a question for a user who is sitting there waiting. Fast responses matter to it even more than they matter to a traditional crawler, and time to first byte in particular may affect AEO performance more heavily than it affects SEO. The fixes are familiar:
- Keep frameworks lean
- Defer non-critical JavaScript
- Render key content server-side so your important copy arrives in the HTML on the first response.
Most AI bots will never run your client-side render. If the copy isn't in the source, it might as well not be on the page.
Semantic HTML and accessibility
Accessibility work and AEO work overlap almost entirely. A useful heuristic is that if a screen reader can parse your page, an LLM probably can too.
Anything you want conveyed through text, images, or video should be accessible to non-visual users, which means alt text for images, transcripts for video, landmark elements that mark page structure, and a heading hierarchy applied consistently.
Structured data
Schema markup is where the AEO sales pitch gets loudest. Testing so far suggests LLMs ingest structured data the way they ingest everything else—as plain text, at face value, rather than as a privileged signal.
Our recommendation, however, is still a strong yes. Traditional SEO and Google search results benefit measurably from properly implemented schema, it may passively support entity-based content strategies, and good SEO remains good AEO. Just don't pay anyone who’s repackaging schema markup as a magical AEO breakthrough.
Emerging tactics: Verdicts on what's worth testing
Past the fundamentals, the advice gets contested. Results, evidence, and official guidance on the tactics below are scattered, and reasonable practitioners will disagree with some of these verdicts. That's fine; the sources are linked so you can weigh them yourself, and the next section covers how to test any of them on your own site.
Llms.txt: Yes, but for agents
An llms.txt file likely does nothing for your odds of being cited in AI answers. The case for it is about agents, because it improves how they interact with your domain and perform actions within it.
There are two developments that support this. Google now evaluates llms.txt presence in Lighthouse's agentic readiness audits (with dedicated guidance on the file itself), and there are documented cases of Claude retrieving llms.txt while working through technical product queries. Wix's AI Search Lab reaches a similar conclusion about where the file's value sits.
That verdict changes what belongs in the file. An agent fetching llms.txt is trying to get work done on your domain, so write it as operational documentation. A useful llms.txt is a plain markdown file at your domain root containing:
- A two-or three-sentence statement of what your company and product are, in language an agent can act on.
- Links to your canonical documentation, grouped by task so an agent can route itself: getting started, integration setup, troubleshooting, account management.
- Your API reference and authentication model, so an agent knows whether it can act programmatically and how to get access.
- Your MCP endpoints, if you expose any (more on that two sections down).
- Markdown versions of key docs, where you offer them, so agents working under token constraints can fetch the lean version directly.
Leave out the marketing copy. There's no ranking algorithm reading this file to be persuaded, and bloating it with positioning language makes the operational content harder for an agent to use, which defeats the file's one real purpose.
Markdown page versions: Not yet, with one exception
The theory is appealing: strip away HTML that might confuse LLMs and serve content in a clean markdown format that parses without friction. The practice doesn't hold up. HTML carries context that markdown strips out, and if LLMs genuinely can't read your pages, you have a deeper technical problem that markdown mirrors won't fix.
Our own research runs counter to the hype here. Profound's markdown-versus-HTML test found a marginal increase in bot traffic to markdown pages, but no conclusive evidence of improved citation rates or accuracy. Google's John Mueller was blunter, calling the bots-only markdown trend "a stupid idea,"
The exception is long, single-purpose content. Documentation that runs long enough to risk token truncation can be worth serving in an optional markdown format, an angle Addy Osmani has explored; the content has one job, and completeness matters more there than EEAT texture. Most ranking content never approaches those limits, and stripping it down risks stripping the signals that earn citations in the first place.
One distinction worth keeping sharp is that offering an optional markdown view that any user or agent can request is a low-risk test. Serving agents a different version of the page than humans see is a separate play, closer to cloaking, and a much bigger gamble.
API and MCP endpoints: Yes, for what's coming
An MCP endpoint skips the entire crawl-ingest-retrieve pipeline. Instead of an agent fetching your pages and reconstructing your product information from prose, it gets a direct port of call for documentation, product data, and whatever structured information you choose to expose. The protocol docs are the right starting point, and nohacks.co's overview frames MCP usefully as a universal adapter for the agentic web.
Exposing an MCP endpoint probably won't lift your citation rates today. What it should improve is the quality, speed, and accuracy of responses about your domain, and it positions you for where agent traffic is heading. Scope what you expose to what your users need, and apply basic hygiene around authentication, rate limiting, and what the endpoint can return.
How to tell if your tests are working
The only way you’ll “figure out” technical AEO is by testing, and every test runs through the same series of steps:
- Pick one change and write down what it should move. "Publishing markdown versions of our API docs will increase retrieval-bot visits to those pages and lift citation rates for documentation prompts" is a testable claim. If you can't name the metric a tactic should influence, you're not ready to ship it.
- Define metrics on both layers. Crawl-level metrics tell you whether bots are reading the pages: bot visits to the target URLs, pages indexed, errors served. Answer-level metrics tell you whether the pages are earning anything: citation rate and accuracy for the prompts those pages should win. Decide both up front, because a result on one layer without the other is half a finding.
- Freeze the baseline. Pull at least four weeks of pre-change data on those exact metrics, from the same source you'll use to measure afterward. Switching measurement tools mid-test invalidates the comparison.
- Ship the change, and nothing else. No other edits to the target pages while the test runs. A quarter in which you shipped llms.txt, restructured internal links, and migrated CDNs tells you nothing about any of them.
- Measure an equal window after, at the page level. Compare the target pages' deltas against their own baselines, not against sitewide averages, where the noise of normal bot behavior will drown out the signal.
- Decide: scale, kill, or extend. Movement on both layers means roll it out wider. Flat on both means kill it and reclaim the effort. Movement on the crawl layer without the answer layer is the most instructive outcome, and it deserves a closer look before you decide.
That last outcome is worth dwelling on, because it's what our markdown research produced: bot traffic to the markdown pages went up, citations didn't, verdict negative. A result like that is the test doing its job, saving you from scaling a tactic that doesn't pay. Crawl movement without answer movement usually means bots can see the change, but the change doesn't alter what's worth citing, and that tells you where to point the next test.
The practical requirement underlying all six steps is to have both layers in one place. Profound’s Agent Analytics covers the crawl layer down to individual pages and crawlers, Answer Engine Insights covers citations and accuracy on the prompts you track. Because they sit on the same platform, the question every test ultimately asks, whether the crawl change became an answer change, is answered from one screen instead of a spreadsheet join.
Page-level deltas across citations, indexing, training, and human referrals: the before-and-after view a test needs, at the granularity sitewide averages can't provide.
Technical AEO: Low impact today, high future potential
The technical work driving AI visibility today is work you should already be doing for SEO, and most emerging hacks have little conclusive evidence to back them. Good SEO is good AEO, and that holds for the technical layer as firmly as anywhere.
The future potential is the more interesting half. Technical SEOs are best positioned in the industry to prepare domains for agentic interaction, and the platforms are signaling where this goes. Google is already auditing agentic readiness through Lighthouse; Anthropic is streamlining how agents integrate with domains; and other LLM providers are following suit. Good technical AEO, then, is two things at once. It's good technical SEO today, and it's a domain that's ready for the agents arriving tomorrow.
Both halves of that job run on the same fuel: visibility into what AI bots are doing on your domain. That's what Agent Analytics provides, from the CDN-level baseline of which crawlers visit and what they read, through crawlability diagnostics that flag robots.txt blocks, rendering failures, and latency issues that keep pages out of answers, to the page-level citation data that turns every tactic in this article into a readable test.
If you'd rather see what AI bots can and can't access on your site before spending a quarter optimizing on guesswork, let’s chat. Our team would love to help.
Technical AEO FAQs
Is technical SEO the same as technical AEO?
Mostly, but not entirely. Good technical SEO gets you most of the way to AI crawlability, and the highest-impact AEO work (permissive bot access, shallow crawl depth, fast TTFB, semantic HTML) is work an SEO team should already be doing. The differences are in emphasis: AI bots don't render JavaScript, are less tolerant of redirect chains and slow responses, and ignore index-management signals like canonicals entirely.
How do I check if AI bots can crawl my website?
AI crawlers don't execute JavaScript, so tools like GA4 never see them. The data lives at the server or CDN layer, in raw server logs, CDN bot dashboards, or a purpose-built tool like Profound's Agent Analytics, which classifies verified AI bot traffic by platform, page, and intent. Start by confirming that your robots.txt isn't blocking crawlers like GPTBot, then check which pages bots can access and where requests fail.
Does schema markup improve AI visibility?
The evidence suggests LLMs read structured data as plain text rather than treating it as a special ranking signal. Implement it anyway: traditional SEO and Google search results still benefit measurably from proper schema, and good SEO remains good AEO. Just be skeptical of anyone selling schema as a dedicated AI optimization breakthrough.
Should I add an llms.txt file to my website?
Yes, with the right expectations. There's no evidence llms.txt improves citation rates, but it improves how AI agents interact with your domain, Google now checks for it in Lighthouse's agentic readiness audits, and there are documented cases of agents retrieving it during technical queries. Treat it as agent documentation: a plain markdown file at your domain root pointing to your docs, API reference, and MCP endpoints, not a marketing surface.
Do markdown versions of pages help with AI search?
Not based on current evidence. Profound's own testing found a marginal increase in bot traffic to markdown pages but no conclusive lift in citation rates or accuracy. The one exception is long, single-purpose content like documentation at risk of token truncation, where an optional markdown version can be worth testing—served alongside the HTML, never as a different version shown only to bots.