Type a buying question into ChatGPT and count the results. There aren't ten. There's one answer, with a handful of brands mentioned inside it, and a point of view about which one fits the person asking. No positions, no page two, no list to climb.
So the honest first response to "how do I rank in ChatGPT" is that the question carries an assumption from another system. There's no ranking to win in the SEO sense. But there’s absolutely a contest happening inside every answer, and brands win or lose it daily.
The work is figuring out what winning means, deciding what you want to win for, measuring where you stand, and then building the signal that influences the answer.
What "ranking" in ChatGPT really means
SEO had a stable unit of measurement because search had a stable unit of demand: the keyword. Thousands of people typed the same two or three words, the engine returned the same list to all of them, and being number one on that list was a prize you could win, hold, and report.
ChatGPT has no perfect direct equivalent. There’s no keyword to be number one for, because there's no fixed result set to hold a position in. In a user experience that collapsed the SERP model, the old metrics have nothing left to attach to.
What replaces them is a set of measurements rather than a single number. Your visibility inside ChatGPT’s answers breaks down into distinct aspects:
- Mentions. Does your brand appear in answers to the questions your buyers ask? This is the closest analog to ranking, and it's the entry ticket.
- Citations. Which sources, yours and others', is ChatGPT pulling from to construct the answer? Citations tell you what's shaping the description of your brand.
- Sentiment and accuracy. How you're characterized matters as much as whether you appear. An answer can name your brand and disqualify it in the same sentence.
That last point is the sharpest break from SEO. In a ranked list, appearing was winning. In a synthesized answer, you can show up, be described inaccurately or unflatteringly, and lose. Which means the question behind "how do I rank" is really "how do I get mentioned, recommended, cited, and described accurately for the prompts that matter to my business."
Decide what you want to be visible for
The reflex, usually inherited from SEO, is to start tracking immediately. You pick some prompts (likely derived from keywords), build a dashboard, and watch the numbers. But tracking without a target produces data you can't act on. With no clear answer to “visible as what, to whom, in which situations,” every data point is interesting, but nothing is actionable.
It helps to hold two pictures in your head. One is how ChatGPT describes your brand today, assembled from every review, comparison article, forum thread, and page of your own site it has absorbed. The other is how you want to be described: the categories you want to own, the use cases where you're the strongest choice, the buyers you serve best. The distance between those two pictures is your entire AEO program.
The second picture needs to be specific to be useful. "We help teams collaborate" gives a model nothing to recommend you for. The working tool here is what we call an attribute list: the concrete, buyer-relevant things you want ChatGPT to associate with your brand, written down and prioritized. Attributes tend to cluster into a few categories:
- The product category terms buyers use, in all their variations
- The industries and verticals you serve, each with its own vocabulary
- The pain points that start a search, phrased the way buyers phrase them
- The use cases that drive retention, which often differ from the ones you market
- The integrations that decide deals
- The personas making the decision
You don't have to invent this list. It's sitting in your sales call recordings, support tickets, review pages, and the community threads where your buyers compare notes.
It's also visible in what people ask AI directly. Profound's Prompt Volumes, built on 1.5+ billion user conversations with AI engines, shows real question volume across answer engines, which is the AEO-native version of keyword research. Pull the themes that recur across several of those sources, then prioritize the ones that influence purchase decisions, where the gap between current and desired description is real, and where you can plausibly make an impact.
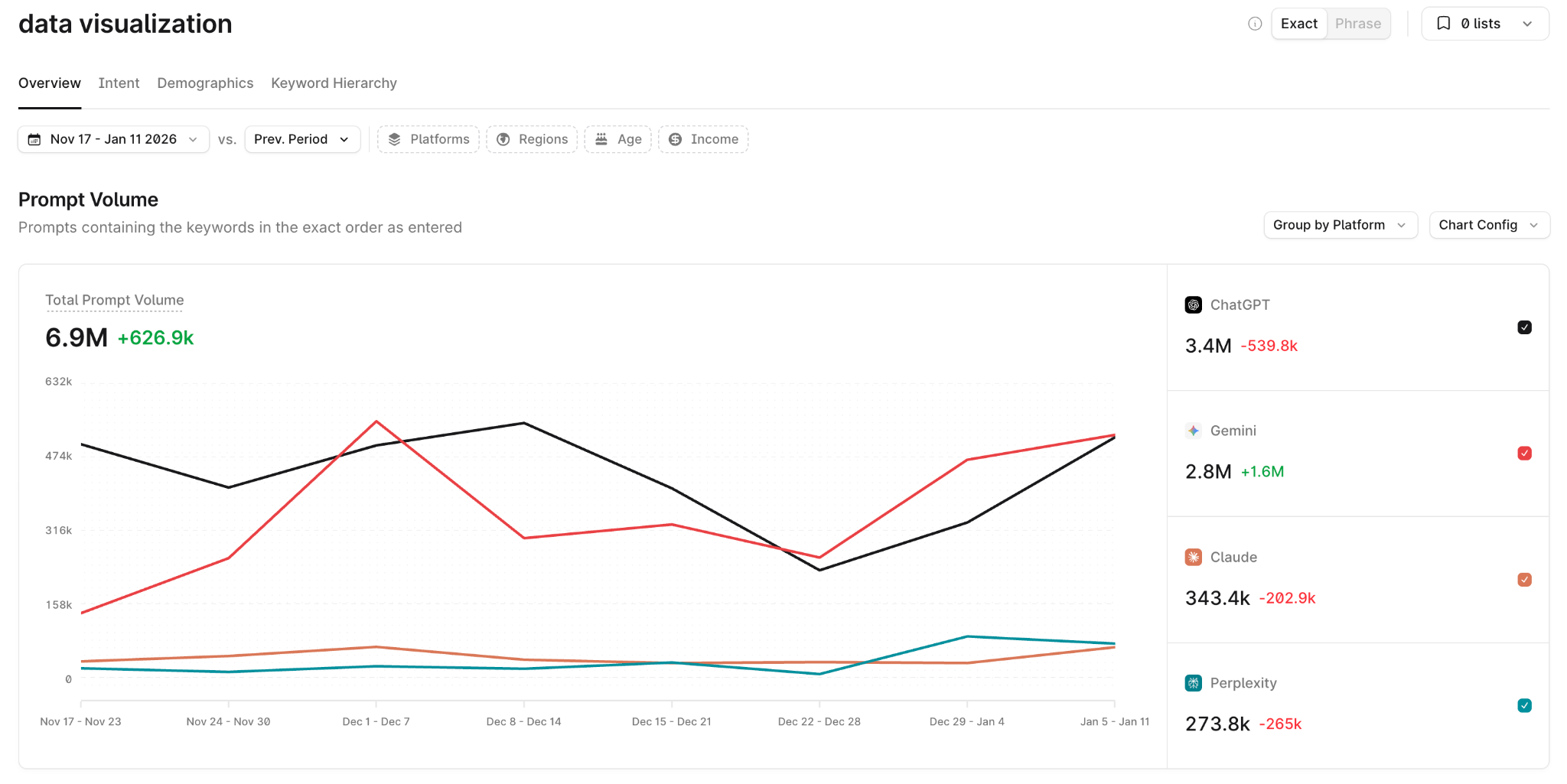
Profound Prompt Volumes draws from 1.5B+ real user conversations with answer engines — showing exactly what people are asking AI, broken down by platform, region, demographics, and intent. No keyword extrapolation.
Benchmark where you stand before you try to change it
The temptation, once the attribute list exists, is to start fixing things immediately. Resist it. Changes made before a baseline can't be evaluated—if you don't capture what ChatGPT says about you today, nothing you ship next quarter can be judged against anything, and you'll be choosing your next move on instinct instead of evidence.
Benchmarking first also tells you which fix to start with. For each priority attribute, two kinds of prompts give you different insights:
- The first asks the way a buyer would, without naming you: "best [category] for [vertical]," "what should a [persona] use for [pain point]." This measures whether ChatGPT surfaces you on its own.
- The second names you directly: "does [your brand] handle [capability]?" This measures whether the model knows you have the capability at all.
The combination is a diagnosis. If ChatGPT neither surfaces you nor credits the capability when asked, it has never absorbed the association, and the fix is content. If it confirms the capability when asked but doesn't recommend you unprompted, it knows you and doesn't trust you enough to put you in the answer, and the fix lives off your site, in third-party corroboration..
You can run this manually at small scale. Ask the prompts in fresh sessions, log who gets mentioned, note the citations, repeat monthly. That strategy, however, becomes infeasible once you're tracking dozens of attributes across personas, regions, and platforms.
Profound’s answer engine optimization (AEO) platform solves that problem. Prompts run continuously across ChatGPT and every other major answer engine, with visibility, citations, accuracy, and sentiment scored over time. The baseline builds itself, stays current as you work, and turns every section that follows into something you can verify and report on.
5 strategies to rank on ChatGPT
What follows are the five areas that impact ChatGPT's answers. None of them is a hack, and they all have a role to play in your pursuit.
1. Understand how ChatGPT searches
ChatGPT rarely answers a commercial question from memory. Before responding, it transforms the user's prompt into several targeted search queries, retrieves what those queries surface, and synthesizes the result. This is what’s called a query fan-out. For example, if you were to ask "which business bank account is best for startups?" the model might also search for startup business checking comparisons, fee breakdowns, and account requirements, then build its answer from whatever those searches return.
The implication is that the queries that decide your visibility are not the prompt the user typed. They're the queries the model generated based on that prompt. Your page can be a perfect answer to the original question and still never appear in the results, because it doesn't surface in the searches the model ran on the user's behalf. From analyzing fan-outs across millions of daily prompts, we can see consistent patterns in how models rewrite intent, adding modifiers like "best," "top," "reviews," and the current year, introducing category terms, and sometimes pulling in competitor names the user never mentioned.
Fan-out is one of three forces stretching every commercial search into the long tail. The second is the prompts themselves: people no longer compress their intent into two-word keywords, because they don't have to. They hand over the full situation, including team size, budget, stack, and constraints. The third is personalization. ChatGPT's memory fills in context that the user didn't type, so two people asking the identical question can receive different recommendations.
Add it up, and the surface you're competing on is thousands of specific, situational queries rather than a few head terms. That's a threat if your brand can only describe itself at the category level, and a real opening if you can document exactly which situations you win. The Query Fanouts view in Profound shows the actual queries behind each prompt you track, so you don’t have to worry about guessing at what ChatGPT searches.
2. Position your brand clearly and consistently, everywhere
ChatGPT's description of your brand is a synthesis of every description it can find. Your homepage gets a vote. So does every review, every comparison article, every partner page, and every forum thread scattered across the web. A company that calls itself a creative operations platform while review sites file it under digital asset management gets described as a muddle of both, and a muddle recommends you to no one.
The work you need to focus on involves:
- Writing the one-page positioning and force the commitment. Answer four answers, in a specific enough way to act on: who you serve, what you solve, why you win, and who you're explicitly not for. The last one is the hardest and the most load-bearing, because a positioning that keeps every door open produces an AI presence that can't be shaped. If the document could describe three of your competitors equally well, it isn't done.
- Rewriting the key sentence on every owned surface. Homepage, about, pricing, and product pages each need to state the positioning in plain, liftable language, because these are the pages models treat as the definitive word on what a company is. The test for each sentence: could ChatGPT quote it directly into an answer and have it make sense? "We're a [category] built for [audience] that [specific job]" passes.
- Hunting down your own contradictions. Positioning drift accumulates in the places nobody reviews: paid landing pages written for a different segment, a three-year-old case study describing a product you've outgrown, footer copy promising "perfect for teams of any size" under an enterprise homepage. ChatGPT absorbs all of it without weighing recency or intent, so every stray claim is a vote against your own consistency. Crawl your own site the way a bot would and fix the stragglers.
- Inventorying how third parties describe you. Pull up your G2 and Capterra category listings, the comparison articles that mention you, and your partners' descriptions of your integration. Note every place where their language diverges from your positioning, because that divergence is exactly what ChatGPT is averaging over. Profound surfaces all of these sources on your behalf: the citation view lists every domain AI pulls from when answering questions about your brand and category, classified as owned, earned, competitor, or social, with the descriptions each one carries. Sentiment scoring shows where the framing skews negative, and accuracy analysis flags the claims AI gets wrong about your product and traces them back to the responsible citations.
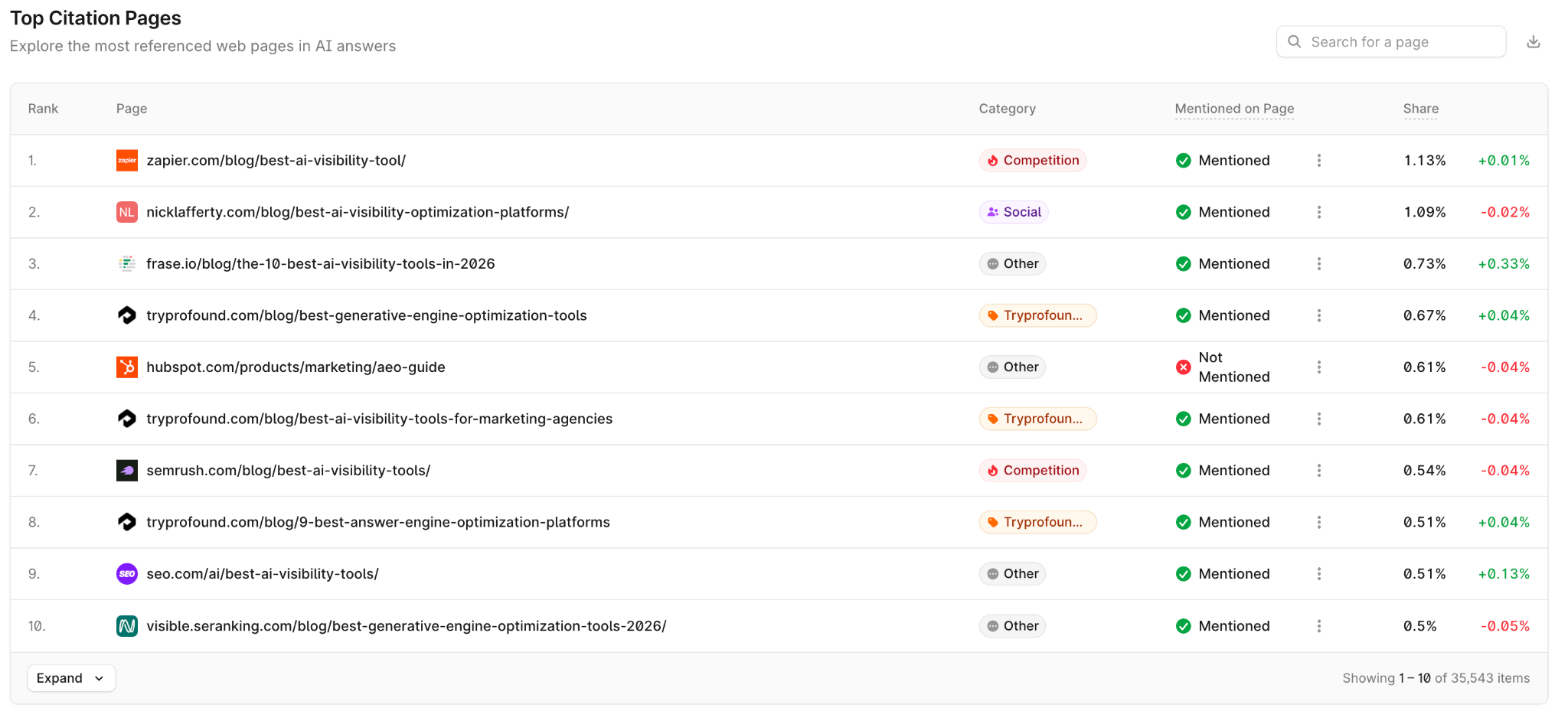
Profound shows the top-cited pages in your category, breaks them down by source, and tells you whether you’re mentioned or absent.
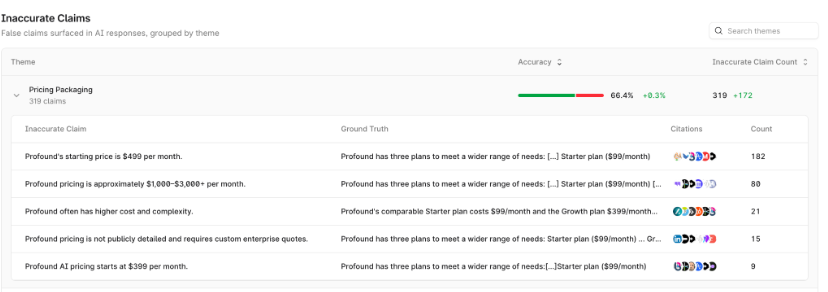
Profound's FactCheck feature surfaces factually wrong AI claims about your brand, traced back to the specific pages that created the opening for misrepresentation.
Every new campaign, landing page, and partner announcement is a fresh chance for drift to creep back in, so if you want to remain consistent, you need to make positioning review a recurring part of the publishing process.
3. Create content that answers the long tail
If the diagnosis says ChatGPT doesn't know what you do, content teaches it. A single page per attribute is the floor; associations get strong enough to shape answers when a capability shows up across multiple pages, each corroborating the others. In order of leverage:
- Create a dedicated page for every priority attribute that lacks one. Each page should state the capability plainly, name who it's for, and back it with specifics: the verticals it serves, the problems it solves, the proof that you deliver it. Write in the language your buyers use in sales calls and reviews, not your internal feature names. ChatGPT can only connect you to a prompt if your page shares the prompt's vocabulary.
- Add reinforcing mentions on the pages ChatGPT already cites. Your citation data in Profound shows which of your URLs appear in AI answers today. A mention of a target attribute added to one of those pages inherits trust the model has already extended, which makes it worth far more than the same mention on a page nothing reads. Work through the cited list and ask, for each target attribute: does this page have a natural place to reference it?
- Reinforce on prominent pages next. Homepage, pricing, about, and comparison pages get heavy crawl attention because that's where models look for definitional claims about a company. An attribute that appears on a dedicated page, a cited blog post, and your pricing page is corroborated three ways; one that lives on a single orphaned URL is a rumor.
- Use FAQs as the quick win. A few genuinely useful questions on existing product and pricing pages give the model clean, extractable blocks, and the best source for them is questions buyers already ask: if you can, pull them from sales calls and support tickets rather than inventing them. The ceiling is a wall of questions that exist only to hit attributes; users recognize it, and it's reasonable to expect AI platforms to discount it the way Google discounted keyword stuffing.
- Weave mentions into existing content where they fit the argument. This is higher effort than FAQs, holds up better over time. If a post is already cited for prompts adjacent to your target attribute, a reference added where it genuinely serves the piece is high-leverage signal. The editorial test: if the sentence would strike an editor who knows nothing about your AEO program as forced, it is, and forced additions tend not to perform.
- Mine your fan-out data for gaps. Every query ChatGPT generates that your site has no answer for is a content gap with purchase intent behind it. Make reviewing those queries a monthly habit: map each recurring fan-out query to the URL that should answer it, and where no URL exists, that's your brief. If ChatGPT keeps searching your category plus a vertical plus "pricing comparison" and that page doesn't live on your domain, someone else's page is filling the slot in your buyers' answers.
The thing to internalize is that this is association-building, not page production. Ten pages that each corroborate three attributes will outperform thirty disconnected posts, so measure progress by re-running your benchmark prompts and watching the associations form, not by counting what you shipped.
4. Make sure ChatGPT can crawl your site
Everything above assumes OpenAI's bots can reach and read your pages, and that assumption fails more often than you'd expect. OpenAI runs three crawlers with different jobs: GPTBot gathers training data, OAI-SearchBot builds the index behind ChatGPT search, and ChatGPT-User fetches pages live while answering. Blocking the wrong one removes you from the corresponding pipeline entirely. The checklist:
- Audit robots.txt for all three bots. Many companies blocked GPTBot in 2023 as a quick legal precaution and never revisited the decision, which today means their content is absent from the answers their buyers read. Check the CDN layer with the same scrutiny: bot-management rules in Cloudflare, Akamai, or Fastly can silently reject non-browser user agents, producing the same invisibility with no paper trail in robots.txt at all.
- Server-render your key copy. AI crawlers don't execute JavaScript, so a page that assembles its product claims client-side serves those bots an empty shell. The check takes a minute: view the raw HTML source of your priority pages and confirm the claims you care about are in it. If they only exist after the render, they don't exist for ChatGPT.
- Get response times down. ChatGPT-User is fetching your page while a user sits waiting for their answer, which makes it far less patient than a traditional crawler. Time to first byte is the metric to watch: keep frameworks lean, defer non-critical scripts, and cache aggressively on the pages you most want cited.
- Keep priority pages shallow and clean. Two to three clicks from the homepage at most, no redirect chains on the way, returning clean 200s. Real-time bots abandon slow or broken paths more readily than Googlebot has trained you to expect, so audit your internal links to key pages more often than your SEO calendar alone would suggest.
This layer is pass/fail in a way the other workstreams aren't: a positioning problem degrades your answers, but a crawl problem deletes you from them. It's also the part Profound covers most directly. Agent Analytics connects at the CDN or server level, where bot traffic is visible, and shows you which AI crawlers visit your site, which pages they read, and where requests fail, with diagnostics that flag the specific blocks and errors keeping pages out of answers. In short, it turns every item on the checklist above into something you can confirm instead of assume.
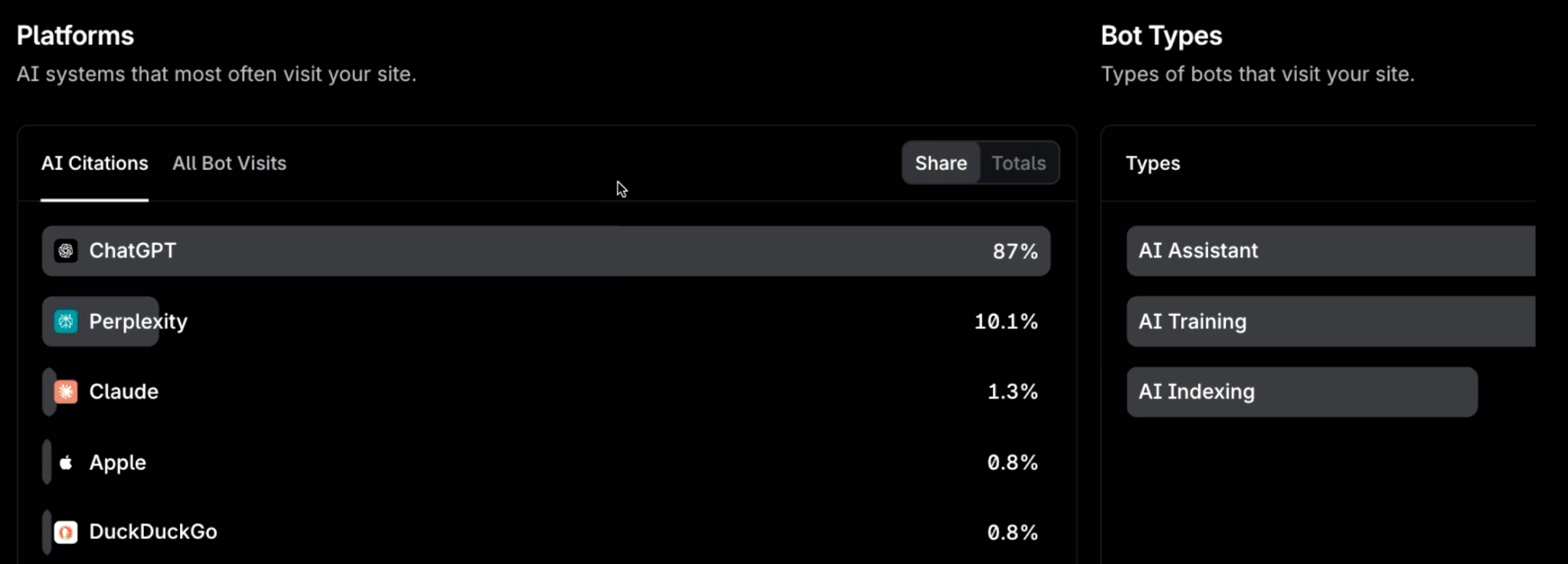
Agent Analytics tracks CDN-level data on which content gets crawled and cited by which LLMs.
5. Influence the sources ChatGPT trusts
Your website is one voice in the chorus. When the diagnosis shows a trust gap (e.g., ChatGPT knows your capability but won't recommend you), the missing ingredient is corroboration from sources you don't control.
For B2B that concentrates on G2, Capterra, integration partners, and trade publications; for consumer brands, it shifts toward Reddit, Trustpilot, and platform-specific communities. Either way, the sources ChatGPT cites for your category form a finite list, and Profound citation data tells you what's on it. Work it in order of friction:
- Pull the citation list and audit it. For each priority attribute, list the third-party sources ChatGPT cites, what each one currently says about you (or fails to say), and whether you have an existing relationship with it: partner, affiliate, investor, customer. Relationships go to the top of the queue, because a routine ask to a warm contact moves faster than any other tactic in this article.
- Fix what already mentions you. Partner integration pages, affiliate posts, and investor portfolio blurbs frequently describe a positioning you abandoned years ago, and a stale description on a page the model already trusts is actively working against you. Make the ask specific: don't request "an update," send the exact replacement language from your positioning doc, because vague asks produce paraphrases and paraphrases reintroduce drift.
- Get added where you're absent. Certain listicles, directories, and review platforms keep appearing in citations for your category, and if competitors are on them while you're not, those sources are doing influence work for someone else. Prioritize by citation frequency rather than domain authority: a niche directory the model pulls from weekly beats a prestigious publication it never reads.
- Create new sources last. Original research that publications pick up, guest posts on domains already in your citation list, and genuine community participation all build influence, but slowly, and only after the faster work above is done. Genuine is the operative word for the community track: manufactured engagement is recognizable, and communities that detect it convert a visibility problem into a reputation problem.
The web's description of your brand has momentum; off-page work is how you steer it.
Start ranking in ChatGPT with Profound
ChatGPT's picture of your brand is an accumulation, and the brands that look inevitable in AI answers a year from now are the ones compounding signal today, with a baseline to prove what's working. Every workstream in this article runs on the same underlying data, and Profound puts all of it in one platform:
- Answer Engine Insights runs your tracked prompts continuously across ChatGPT and every other major answer engine, scoring visibility, citations, and sentiment over time.
- Query Fanouts expose the exact searches ChatGPT runs behind each prompt, so your content targets what the model retrieves instead of what you assume it does.
- Prompt Volumes, built on 1.5+ billion real user conversations with AI, show what people ask ChatGPT in your category.
- Agents turn the findings into output: drag-and-drop workflows take content from brief to draft to optimization to publishing inside Profound.
- Agent Analytics confirms OpenAI's crawlers can reach and read your pages, with CDN-level tracking and diagnostics that flag what's blocking you.
If you want to start with the measurement layer already built, book a demo with our team.
How to rank in ChatGPT FAQs
Does my existing SEO content count toward AI visibility, or do I need to start from scratch?
Existing content counts, but not uniformly. Pages already being crawled and cited by AI answer engines carry weight regardless of whether they were written with AEO in mind. The question is whether those pages make clear, extractable claims about the attributes you want to be known for, or whether they’re written in a way that’s hard for AI to pull signal from—broad category descriptions, feature lists, marketing language that gestures at outcomes without naming them.
In most cases, refreshing existing content with more specific, direct language produces faster results than publishing from scratch, because the pages already have crawl history behind them. A content audit against your attribute list will surface which pages are working, which need updating, and where the genuine gaps are.
How long does it take for changes to show up in AI answers?
It varies by platform and by the type of change, and there’s no published re-indexing cadence from any of the major answer engines. Changes to pages AI is already actively crawling tend to register faster than new pages being discovered for the first time. Off-page changes can take weeks to propagate, depending on how often those sources are crawled.
Run a prompt baseline before making changes so you have something to compare against, then check the same prompts at two-week intervals rather than daily. Daily checking creates noise; two-week intervals give the model enough time to re-read the source and incorporate it.
Is this only relevant for B2B companies, or does it apply to consumer brands too?
The mechanics apply to any brand that wants to appear in AI-generated answers, but the stakes and the starting point differ. B2B buying journeys are longer, more research-intensive, and more likely to involve AI as a serious evaluation tool—which is why the ROI case for this work is clearest there. Consumer brands face a different version of the same problem: AI is increasingly embedded in shopping, product discovery, and comparison queries.
The attribute list approach, the content strategy, and the off-page inventory work the same way regardless of audience. What changes is which prompts you track, which sources matter most, and what “accurate description” looks like for your category.
What’s the difference between AEO and SEO, and do I need to choose between them?
You don’t need to choose, but treating them as the same discipline produces a weaker version of both. SEO is built around keywords, links, and ranked positions. AEO is built around prompts, citations, and the accuracy of what gets said about your brand. The optimization targets are different, the content requirements are different, and the measurement frameworks are different.
In practice, good AEO work often strengthens SEO performance because content written to address specific buyer prompts tends to be more substantive than content written purely to rank for a head term. The reverse isn’t reliably true: a page optimized for a high-volume keyword may rank well in Google and never get cited in an AI answer, because the content is too broad to extract from. The most defensible position is a program that does both with distinct goals for each.